-
- Date(descending)
- Date(ascending)
-
July 21, 2026 Read More
Trade (Consumer Book) Revenues Up 7.6% for Month of May, and Up 2.3% Year-to-Date
Today, the Association of American Publishers (AAP) released its StatShot report covering May 2026, reflecting reported revenue for Trade (Consumer Books), Education (combines PreK-12 Instructional Materials and Higher Education Course Materials), and Professional & Scholarly Publishing.
Total revenue across all categories for May 2026 was up 6.8% as compared to May 2025, coming in at $931.1 million. Year-to-date revenues were up 2.6%, at $4.7 billion.
Trade (Consumer Books) Revenues
May
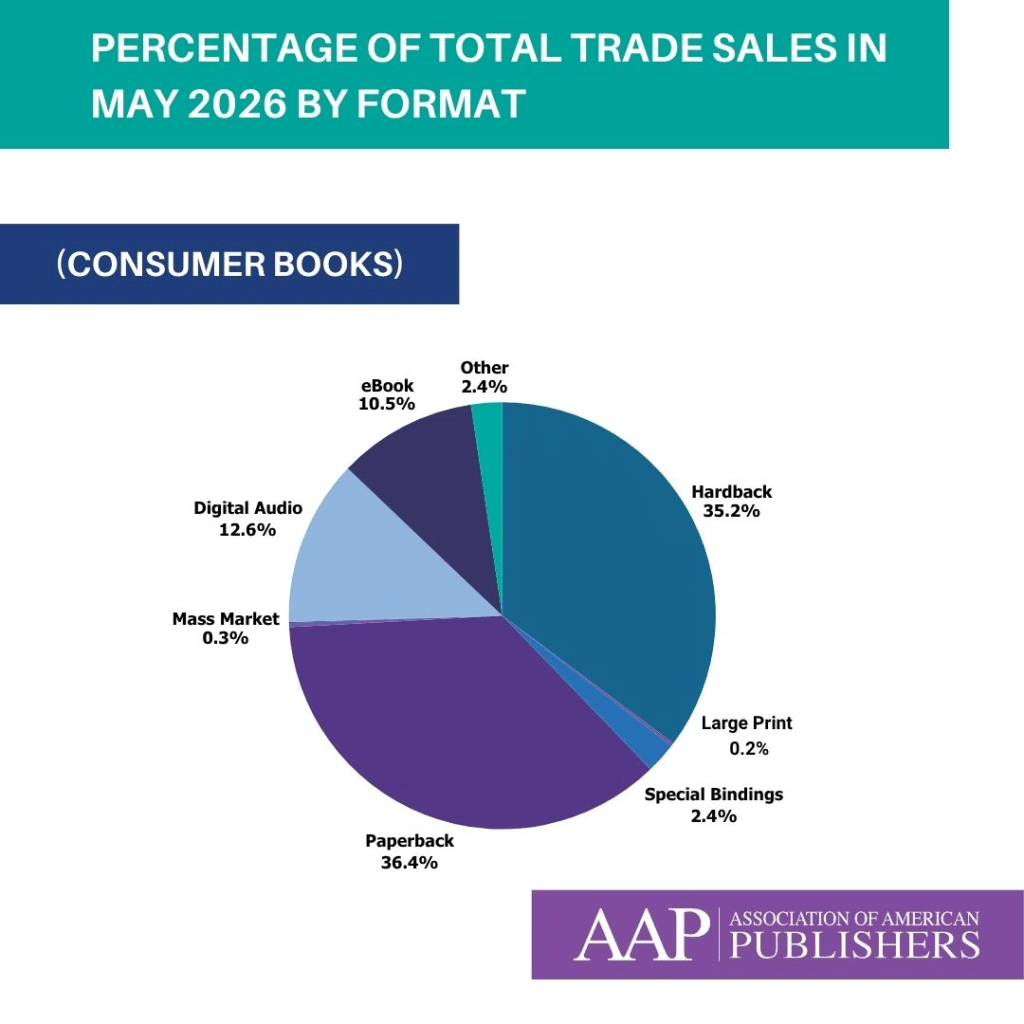
Trade (Consumer Books) revenues were up 7.6% in May at $799.5 million. In terms of physical paper format revenues during the month of May, in the Trade (Consumer Books) category, Hardback revenues were up 7.4%, coming in at $281.5 million; Paperbacks were up 10.4%, with $290.8 million in revenue; Mass Market was down 73.8% to $2.5 million; and Special Bindings were up 25%, with $18.9 million in revenue.
eBook revenues were down nearly 1% at $84.2 million for the month, and revenues from the Digital Audio format were up 13.0% for May, coming in at $100.7 million in revenue. Physical Audio revenues were up 16.3%, coming in at $500 thousand.
Year-to-date
Trade revenues were up 2.3% at $3.8 billion for the year. Hardback revenues were down 3.2%, coming in at $1.3 billion; Paperbacks were up 6.6%, with $1.4 billion in revenue; Mass Market was down 75.6% to $10.1 million; and Special Bindings were up 26.1%, with $94.6 million in revenue.
eBook revenues were down 3.5% compared to 2025, for a total of $429.7 million. The Digital Audio format was up 14.5%, coming in at $500.4 million in revenue. Physical Audio revenues were down 6.3%, coming in at $2.2 million.
Religious Presses Up 9.3% In May
Religious Press revenues were up 9.3% compared to the same month in 2025, coming in at $69 million. Hardback revenues were up 4.9% to $38.8 million in revenue, Paperback revenues were up 27.8% to $13.8 million, eBook revenues were up 23.5% coming in at $4.4 million, and Digital Audio revenues were up 8.8% at $4.1 million.
On a year-to-date basis, Religious press revenues were up 0.9% during the first five months of 2026, coming in at $351.1 million. Hardback revenues were down 2.6% to $205.4 million in revenue, Paperback revenues were up 7.3% to $68.2 million, eBook revenues were up 3.6% at $21.5 million, and Digital Audio revenues were up 2.9% at $20.5 million.
Professional & Scholarly Publishing Down 3.3% for May 2026
Professional & Scholarly Publishing, including business, medical, law, technical, scientific, and other books, was down 3.3% for May of 2026, coming in at $30 million. The category was up 2.8% for the first five months of the year, coming in at $166.6 million.
Education Materials (combines PreK-12 Instructional Materials and Higher Education Course Materials) Up 1.1% for May 2026
During May 2026, revenues from Education Materials were $88.9 million, up 1.1% compared with May 2025. Year-to-date, Education Materials revenues were $672.7 million, up 3.2% compared to the first five months of 2025.
AAP’s StatShot
AAP StatShot reports the monthly and yearly net revenue of publishing houses from U.S. sales to bookstores, wholesalers, direct to consumer, online retailers, and other channels. StatShot draws revenue data from more than 1,416 publishers, although participation may fluctuate slightly from report to report.
StatShot reports are designed to give ongoing revenue snapshots across publishing sectors using the best data currently available. The reports reflect participants’ most recent reported revenue for current and previous periods, enabling readers to compare revenue on both a month-to-month and year-to-year basis within a given StatShot report.
Monthly and yearly StatShot reports may not align completely across reporting periods, because: a) The pool of StatShot participants may fluctuate from report to report; and b) Like any business, it is common accounting practice for publishing houses to update and restate their previously reported revenue data. If, for example, a business learns that its revenues were greater in a given year than its reports first indicated, it will restate the revenues in subsequent reports to AAP, permitting AAP in turn to report information that is more accurate than previously reported.
-
Today, the U.S. District Court for the Northern District of California granted final approval of the parties’ proposed class settlement of certain infringement claims in Bartz v. Anthropic. The agreement requires Anthropic to pay $1.5 billion to the authors and publishers of nearly half a million books it downloaded from notorious pirate sites, as well as destroy all the original files of works torrented and downloaded from those sites and any copies that originate from the torrented copies. In aggregate, this decision marks the largest class action copyright settlement in history, with a reported claims rate of 92.77 percent. As defined by the court, the class includes legal or beneficial copyright owners, specifically the owners of the exclusive right to reproduce copies, of any book that was downloaded by Anthropic through Library Genesis (LibGen) in June 2021 or from Pirate Library Mirror (PiLiMi) in July 2022, has an International Standard Book Number (ISBN) or Amazon Standard Identification Number (ASIN), was registered with the U.S. Copyright Office within five years of first publication, and was registered before being downloaded by Anthropic, or within three months of first publication. The class covers hundreds of thousands of works of AAP member companies and their authors, and many other works.
Statement from AAP President and CEO Maria A. Pallante:
“We applaud the court’s final approval of this settlement, which represents an important victory in the larger battle to hold big tech accountable for its unscrupulous appropriation of intellectual and creative properties that clearly belong to authors and publishers. In this case, the court recognized that downloading from pirate sites is not a choice we should simply accept as an efficiency for the infringer; on the contrary, it’s abhorrent conduct that should never be normalized.
Nor should fair use extend to training, which can easily be licensed like every other digital use in the modern copyright economy. Tech companies might like a copyright law with a giant hole in the place of exclusive rights, but that law does not exist. Partnerships, not piracy, are the best path forward.”
The order granting final approval can be found here.
-
July 10, 2026 Read More
Today, three major publishing houses, Hachette Book Group, Inc., Cengage Learning, Inc., and Elsevier Inc., and best-selling author Scott Turow filed a putative class action lawsuit against Google for willful infringement of millions of textual works to develop Google’s Gemini large language models. Plaintiffs bring these claims on behalf of themselves and a proposed class of authors and publishers.
The scope of the complaint underscores that authors and publishers are united in the goal of protecting their valuable intellectual property rights in works of fiction, nonfiction, children’s books, memoirs, and poetry, as well as educational works and scholarly articles that span thousands of subject areas and research developments. While publishers had initially intended to pursue their claims against Google for its brazen infringement as intervenors in the ongoing litigation known as In re Google Generative AI Copyright Litigation, the filing of this suit at this time aims to preserve the right to pursue all the claims that publishers and their authors have against Google, including important ones that fall outside the putative class in that case.
As explained in the complaint, Google illegally copied countless books and journal articles obtained for strictly limited use in Google Books and other Google services and downloaded unauthorized web scrapes of virtually the entire internet, including from known pirate sources and behind paywalls. Google further copied “those stolen works many times over to train its multi-billion-dollar generative AI system called Gemini.” Google also stripped copyright management information from the stolen works to conceal its training sources and facilitate their unauthorized use. Google then deployed its “purpose-built service designed to generate content that directly substitutes” for original works.
The complaint alleges examples showing that Google knew it lacked authorization to copy the works for AI training, including:
- Google flagged internally that using “Publisher Provided [] copyrighted books” from Google Play Books in connection with its AI was “highly problematic for Google,” warning of “$10Bs-$100Bs in potential fines.”
- Google identified specific business and legal risks associated with secretly training on Google Play Books, including that “Book publishers [are] likely to see LLM training on their books as copyright infringement. Could withdraw their content from Google Play Books file a lawsuit against Google.”
- Google’s internal analyses identified key “issues” around using Google Play Books to train AI, including “Restrictive licenses for certain partner Books content[]; “Publishers are sensitive about training on their data”; and “Heightened risk around fair use defenses.”
- Copyright owners told Google that it was not authorized to use works provided for these limited-purpose programs outside of the scope-limited programs for which the works had been provided, including to train Google’s AI models.
Plaintiffs are represented by Oppenheim + Zebrak, LLP and Keller Rohrback.
Read the full complaint here.
-
June 24, 2026 Read More
Trade (Consumer Book) Revenues Up 3.6% for Month of April, and Up 1% Year-to-Date
Today, the Association of American Publishers (AAP) released its StatShot report covering April 2026, reflecting reported revenue for Trade (Consumer Books), Education (combines PreK-12 Instructional Materials and Higher Education Course Materials), and Professional & Scholarly Publishing.
Total revenue across all categories for April 2026 was up 4.4% as compared to April 2025, coming in at $887.7 million. Year-to-date revenues were up 1.7%, at $3.7 billion for the year.
Trade (Consumer Books) Revenues
April
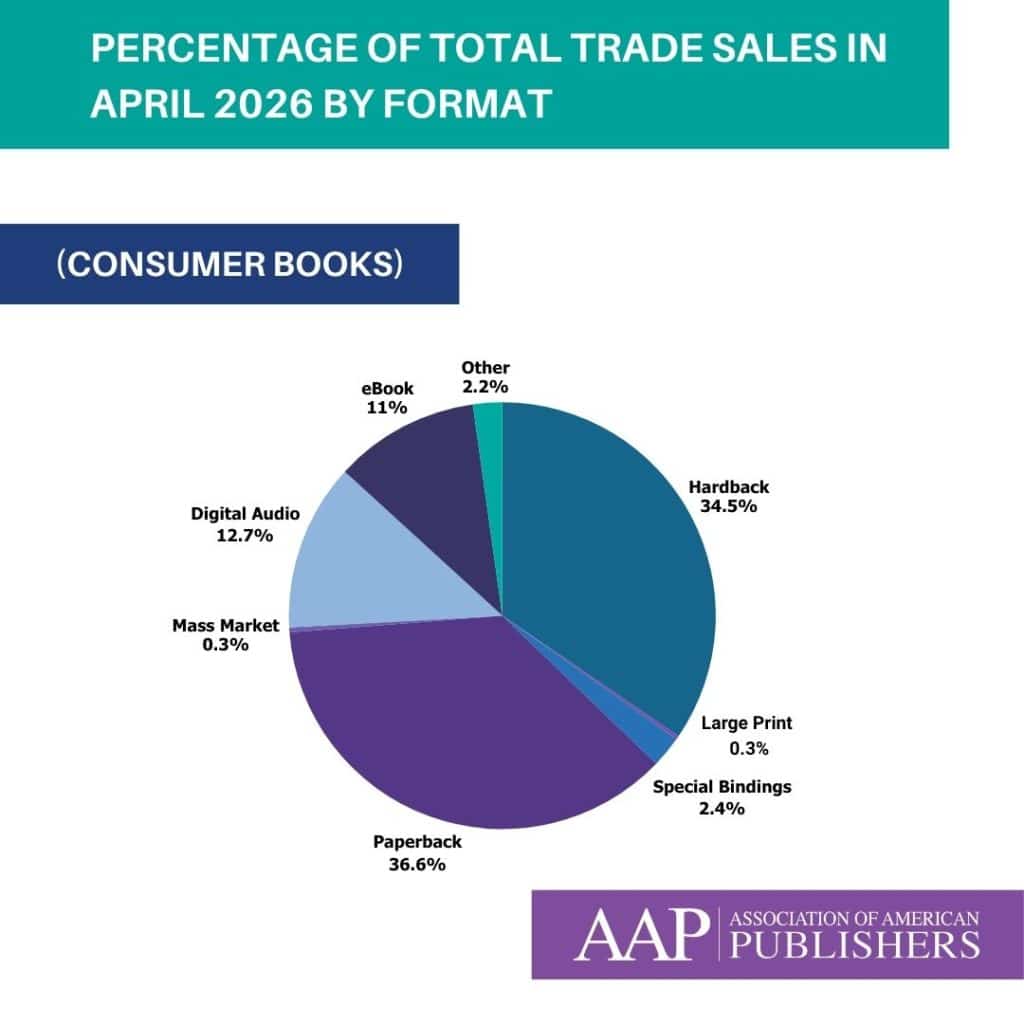
Trade (Consumer Books) revenues were up 3.6% in April at $768.9 million. In terms of physical paper format revenues during the month of April, in the Trade (Consumer Books) category, Hardback revenues were down 3.1%, coming in at $265.8 million; Paperbacks were up 10%, with $281.4 million in revenue; Mass Market was down 77.2% to $2.4 million; and Special Bindings were up 44.4%, with $18.3 million in revenue.
eBook revenues were down 1.2% at $84.6 million for the month, and revenues from the Digital Audio format were up 11.9% for April, coming in at $97.5 million in revenue. Physical Audio revenues were down 12.3%, coming in at $400 thousand.
Year-to-date
Year-to-date Trade revenues were up 1.0% at $3 billion for the year. Hardback revenues were down 5.6% on a year-over-year basis, coming in at $1.0 billion; Paperbacks were up 5.6%, with $1.1 billion in revenue; Mass Market was down 76.2% to $7.6 million; and Special Bindings were up 26.4%, with $75.7 million in revenue.
eBook revenues were down 4.1% compared to 2025, for a total of $345.6 million. The Digital Audio format was up 14.9%, coming in at $399.7 million in revenue. Physical Audio revenues were down 11.6%, coming in at $1.7 million.
Religious Presses Up 2.8% In April
Religious press revenues were up 2.8% as compared to the same month in 2025, coming in at $63.7 million. Hardback revenues were down 0.8% to $37.6 million in revenue, Paperback revenues were up 10.8% to $11.6 million, eBook revenues were down 1.6% coming in at $3.9 million, and Digital Audio revenues were up 0.8% at $3.9 million.
On a year-to-date basis, Religious press revenues were down 0.5% during the first four months of 2026, coming in at $283.3 million. Hardback revenues were down 3.5% to $167.8 million in revenue, Paperback revenues were up 3.2% to $54.1 million, eBook revenues were flat at $17.2 million, and Digital Audio revenues were up 1.8% at $16.4 million.
Professional & Scholarly Publishing Up 0.3% for April 2026
Professional & Scholarly Publishing, including business, medical, law, technical, scientific, and other books were up 0.3% for April of 2026, coming in at $33.3 million. The category was up 4.3% for the first four months of the year coming in at $137.4 million.
Education Materials (combines PreK-12 Instructional Materials and Higher Education Course Materials) Up 5.5% for April 2026
During April 2026, revenues from Education Materials were $74.1 million, up 5.5% compared with April 2025. Year-to-date Education Materials revenues were $583.8 million, up 3.5% compared to the first four months of 2025.
AAP’s StatShot
AAP StatShot reports the monthly and yearly net revenue of publishing houses from U.S. sales to bookstores, wholesalers, direct to consumer, online retailers, and other channels. StatShot draws revenue data from more than 1,416 publishers, although participation may fluctuate slightly from report to report.
StatShot reports are designed to give ongoing revenue snapshots across publishing sectors using the best data currently available. The reports reflect participants’ most recent reported revenue for current and previous periods, enabling readers to compare revenue on both a month-to-month and year-to-year basis within a given StatShot report.
Monthly and yearly StatShot reports may not align completely across reporting periods, because: a) The pool of StatShot participants may fluctuate from report to report; and b) Like any business, it is common accounting practice for publishing houses to update and restate their previously reported revenue data. If, for example, a business learns that its revenues were greater in a given year than its reports first indicated, it will restate the revenues in subsequent reports to AAP, permitting AAP in turn to report information that is more accurate than previously reported.
-
The Association of American Publishers (AAP) announced a major infringement suit today against WeLib, a for-profit pirate site that has made clear its purpose is “to illegally obtain, reproduce, distribute, and profit from works of authorship without regard to the authors, illustrators, publishers, and other creators who own, exercise, license, and make a living from their intellectual property.”
The suit, which was brought by thirteen publishing companies across the trade, educational, and professional and scientific publishing sectors, follows a similar infringement suit against the notorious pirate site Anna’s Archive. Publishers prevailed in that case last month when the United States District Court for the Southern District of New York issued a sweeping default judgment against Anna’s Archive on May 19, levying the maximum statutory damage award for each of the 130 works in the suit and ordering all domain name registries and registrars for Anna’s Archive and all hosting and internet service providers for its websites to disable access to Anna’s Archive and prevent their transfer to anyone other than the plaintiffs. The judgement also directed international providers to stop hosting the site.
Statement from Maria A. Pallante, AAP President and CEO:
“WeLib steals, distributes, and profits from millions of literary, educational, and scientific works from its cowardly locations on the internet, in the process injuring authors, publishers, and the public. Today’s action is part of our ongoing and vigorous response to the mass theft of literary works, which has no place in the modern world and cannot be tolerated.”
Excerpts from the complaint include:
- Defendants have deliberately violated the copyright law of the United States.
- Defendants boast that they have reproduced “an endless collection of literature, research papers, and education materials,” none of which they own or have licensed.
- Publishers bring this action to stop the mass distribution by Defendants of millions of legally protected literary works owned by Publishers that were unlawfully copied from physical and digital books and journals. Publishers’ action is now especially critical in light of reports that major large language model developers used illegal sites like WeLib as illicit sources of training data.
- They claim this stolen collection spans “every genre – from timeless masterpieces to the latest scholarly publications.”
- Through its various websites—including welib.org, welib.st, and welib-public.org (together, the “Website”)—WeLib hosts over 43 million books and 98 million papers. Its stolen collection of literary works has purportedly attracted over 80,000 active monthly users. According to the Website, WeLib’s users have illegally accessed over 51 million books in the last month alone, or an average of over 1.7 million books per day.
- Defendants profit directly from their mass infringement business.
- For the copyrighted content hosted directly by WeLib, download speeds for free users are typically very slow. However, in exchange for a “donation,” users receive “fast downloads” and avoid waitlists. In reality, these “donations” are paid memberships. Given the volume of the pirated files WeLib encourages its users to download, buying this extra download speed is a practical necessity. WeLib accepts payment for these faster downloads through its “Donate” webpage. Its paid subscriptions start at $7 per month for “25 fast downloads per day” and “25 fast reads per day.” On the higher end, for $90 a month WeLib offers “1000 fast downloads per day” and “1000 fast reads per day.”
About the Association of American Publishers
The Association of American Publishers (AAP) represents the U.S. publishing industry on matters of law and policy, with a particular focus on the copyright, technology, and freedom of expression issues that make publishing possible. Founded in 1970, AAP regularly organizes and supports litigation that is of existential importance to the greater creative community. AAP’s members include large, small, and specialized publishing houses serving both local and global markets. Together, they inform and inspire the public, one work of authorship at a time.
About the Plaintiffs
Plaintiffs in Apress Media, LLC et al. v. WeLib and Does 1 - 10 include Apress Media, LLC; Cengage Group; Elsevier Inc.; Hachette Book Group, Inc.; HarperCollins LLC; John Wiley & Sons, Inc.; Bedford, Freeman & Worth Publishing Group, LLC d/b/a Macmillan Learning; Macmillan Publishing Group, LLC; McGraw Hill LLC; Pearson Education, Inc.; Penguin Random House LLC; Simon & Schuster, LLC; Taylor & Francis Group, LLC.
The plaintiffs, and other AAP member publishers, publish and curate the important, beloved, and award-winning works of many of the world’s most acclaimed authors as well as leading educators and experts in various educational, scholarly, and scientific fields. They are global leaders who partner with brilliant authors to deliver works that educate, inform, and inspire every type of reader.
Read the full complaint here.
